
Coding tokens
The linguistic subfield of language variation and change studies linguistic variables: speakers’ choices between multiple linguistic forms that exist in the same linguistic environment. For example, some speakers of Pittsburgh English pronounce the /aw/ vowel (the vowel sound in words like out and downtown) more like “ah” (stereotyped as “aht” and “dahntahn”). The multiple forms of the /aw/ variable (“aw” and “ah”) are known as variants. In order to research this variable, a researcher has to listen to every token of /aw/ and manually identify whether the speaker pronounced it as “aw” or “ah”. This process, which is called coding, is often tedious and time-consuming.
Fortunately, APLS makes coding much easier and faster. On this page, we’ll discuss three common coding scenarios:
- Variables for which codes can be extracted from annotations without you needing to manually code tokens
- Variables that can be coded based on the text of the transcript alone
-
Variables for which you need to listen to transcript audio in order to code them
This is often the most challenging of the three coding scenarios. To make it easier and faster, we’ve created a program,
CodeTokens.praat.
While this page focuses mosly on coding variants, these scenarios can also apply to predictors. Not covered on this page is measuring tokens’ acoustic properties, which you might want to do instead of (or in addition to) coding them.
If you haven’t yet, read the documentation section on searching the corpus and the page on exporting data before reading this page.
On this page
The coding workflow
The coding (and data analysis) workflow usually looks something like this:
- Create a search where each match is one token of the variable you’re interested in, for the participants and/or transcripts in your sample.
- This can take some trial and error!
- Export search results to CSV.
- If coding by listening to audio, export utterances as Praat TextGrids and audio files as well.
- Enter codes in a new CSV column.
- CSVs can be read and edited in spreadsheet programs like Microsoft Excel, Numbers for Mac, or Google Sheets.
- If coding by listening to audio, you can use the
CodeTokens.praatPraat script to make this much faster.
- If needed, code predictors (aka independent variable(s) or constraints) in new CSV column(s).
- Use a program like Excel or R for statistical modeling and/or data visualization.
Coding tokens by extracting annotations
In this scenario, annotations that are already in APLS provide the codes. This works well for many lexical variables (like slippy vs. slippery), morphological variables (like don’t vs. doesn’t), and syntactic variables (like will vs. going to vs. gonna). In each of those cases, you can export annotations on the orthography layer.
In some cases, you still might need to categorize or relabel exported annotations into variants in order to get your codes. For example, if you’re looking at a set of “Pittsburghese” lexical items, you might need to create a new CSV column that categorizes some orthography annotations as Pittsburgh (such as slippy, nebby, sweeper) and others as non-Pittsburgh (such as slippery, nosey, vacuum).
With these variables, the tricky thing isn’t coding, it’s figuring out which forms are actual tokens of the variable vs. unrelated forms, and encoding that in your search. For example, if you’re investigating English future-tense variation (will vs. going to vs. gonna), you’ll want to exclude forms that aren’t in the future tense (like “a strong will” or “going to the store”). In this particular example, you can use the part_of_speech layer to only include will tokens that are modal verbs (part_of_speech MD) and going to tokens where the to is an infinitival marker (part_of_speech TO). In other situations, you might have to consult the context of the words in the transcript to figure out which tokens to include or exclude.
Not for phonological variables
This scenario generally doesn’t apply to phonological variables (like [ɪŋ] vs. [ɪn] endings in words like working or something). Instead, these variables need to be coded by listening to audio.
This is because annotations on phonological layers like segment are phonemic, not phonetic. To generate the segment layer, APLS first uses pronouncing dictionaries to match each word’s orthography annotation to a phonemic representation (like /ˈwɝɹkɪŋ/ for working, /ˈsʌmθɪŋ/ for something), then uses the HTK algorithm to find the start and end time of each of these sounds. While some orthography annotations have multiple phonemic representations in the dictionary, this is restricted to homophones (like desert as /dəˈzɝt/ vs. /ˈdɛzɚt/) or reduced vs. unreduced pronounciations of highly common words (like to as /tə/ vs. /ˈtu/). As a result, working and something are always represented in APLS as ending with /ɪŋ/, regardless of whether the speaker said [wɝɹkɪŋ] or [wɝɹkɪn].
Coding tokens by reading context
In this scenario, coding is done manually by looking at the context of the words in the transcript. In the previous scenario, the codes come from the form of the token (that is, the annotation); in this scenario, the codes come from the meaning or function of the token. This works well for variables such as like, which can be a verb on its own (“I would like that”), part of the quotative verb be like (“she was like, ‘what do you mean?’”), a preposition (“things like that”), a subordinating conjunction (“like I said”), or a discourse particle (“my like role model”).
On the Search results page, you can use the context selector to view the entire text of the utterance that contains each token. Here’s what that looks like for a simple search for orthography like:
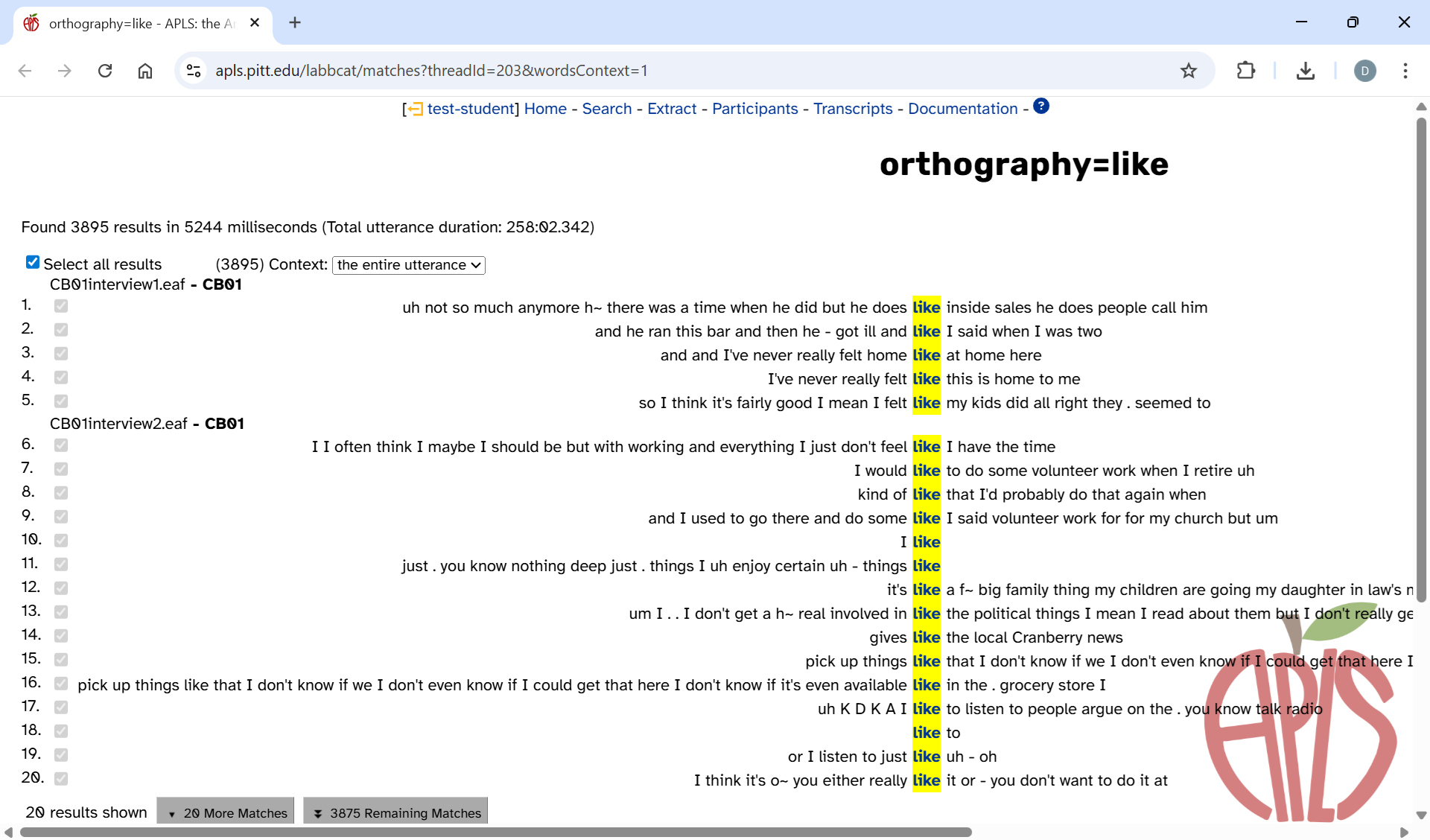
This search also uses the Only include matches from the main participant in a transcript search option.
Then you can enter codes in a new column in your results CSV file. If you’re using Windows, you can use Snap to put your browser and CSV file side-by-side:
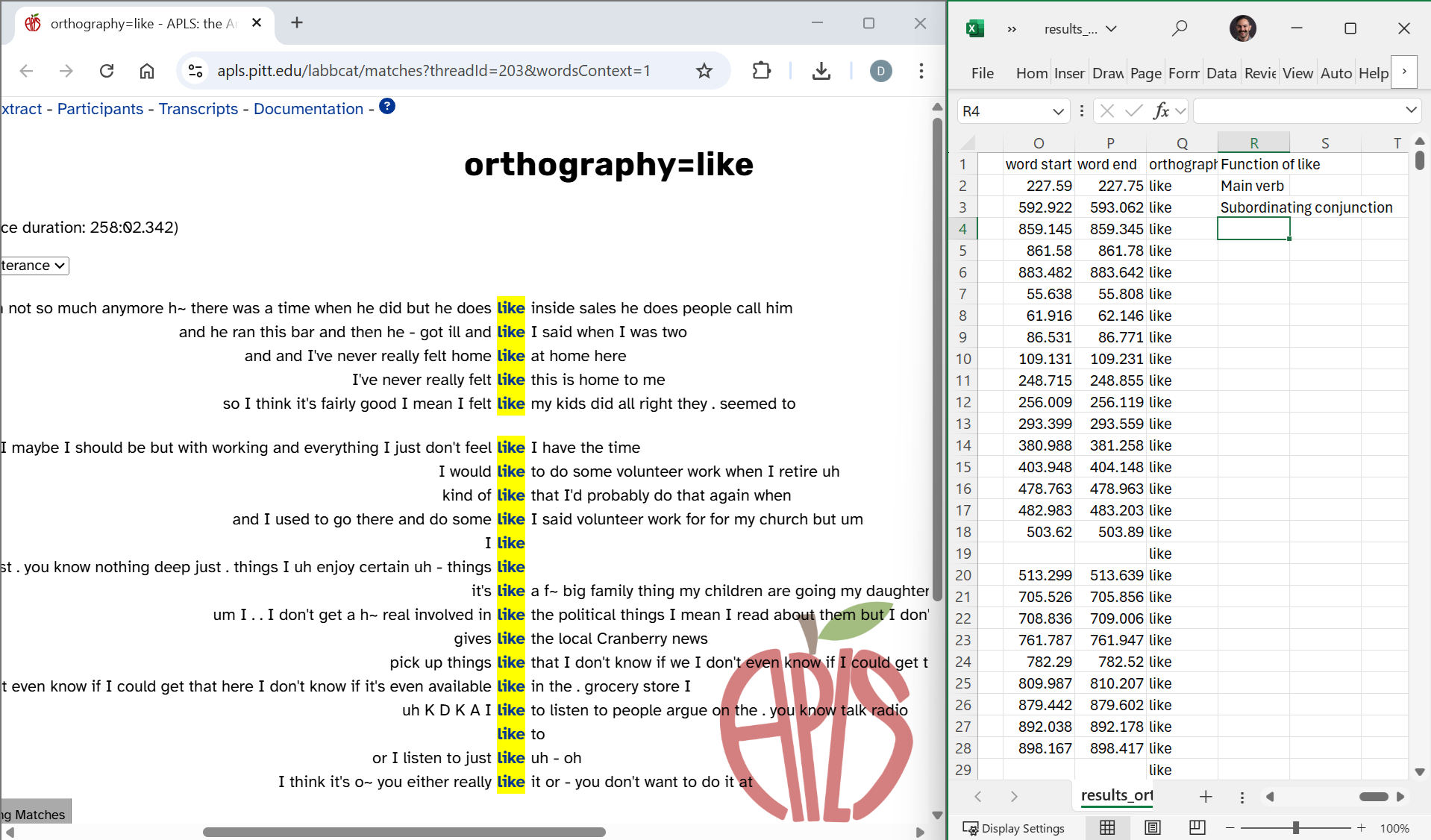
You might also find it convenient to hide columns in the CSV file (Excel instructions) so you can make sure you’re coding the correct row:
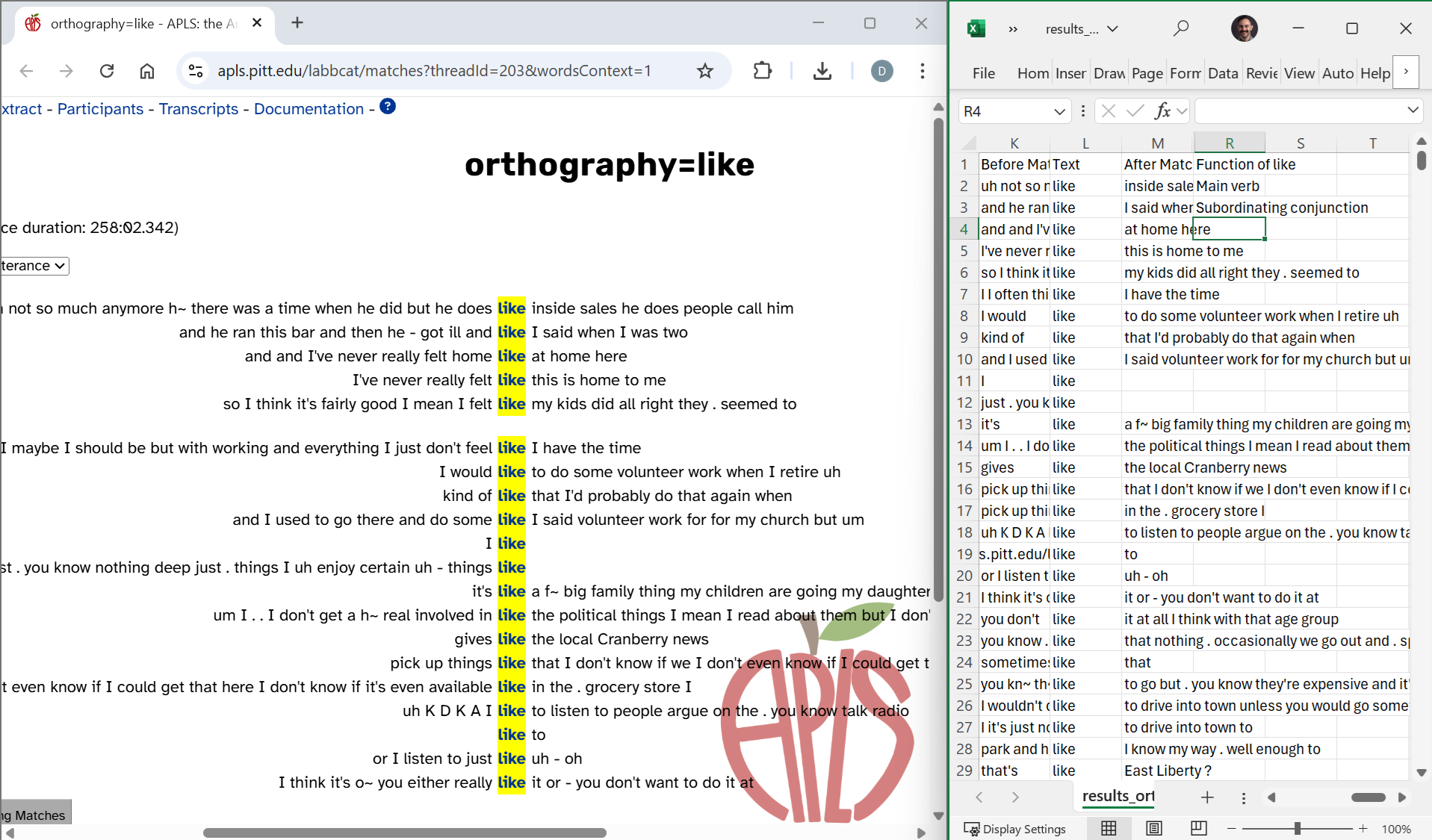
Since the Before Match, Text, and After Match columns show the same search context that’s on the Search results page, you can use only the CSV file if you don’t want to use multiple windows. This can be useful if you have a lot of tokens to code and can’t count on internet access the whole time. That said, it does take some tweaking of the display settings to look nice. Here’s what it looks like in Excel when you hide all columns except those three and the coding column, adjust the column widths, select Wrap text so the whole context is visible when it’s long, and adjust row heights so they’re not too tall:
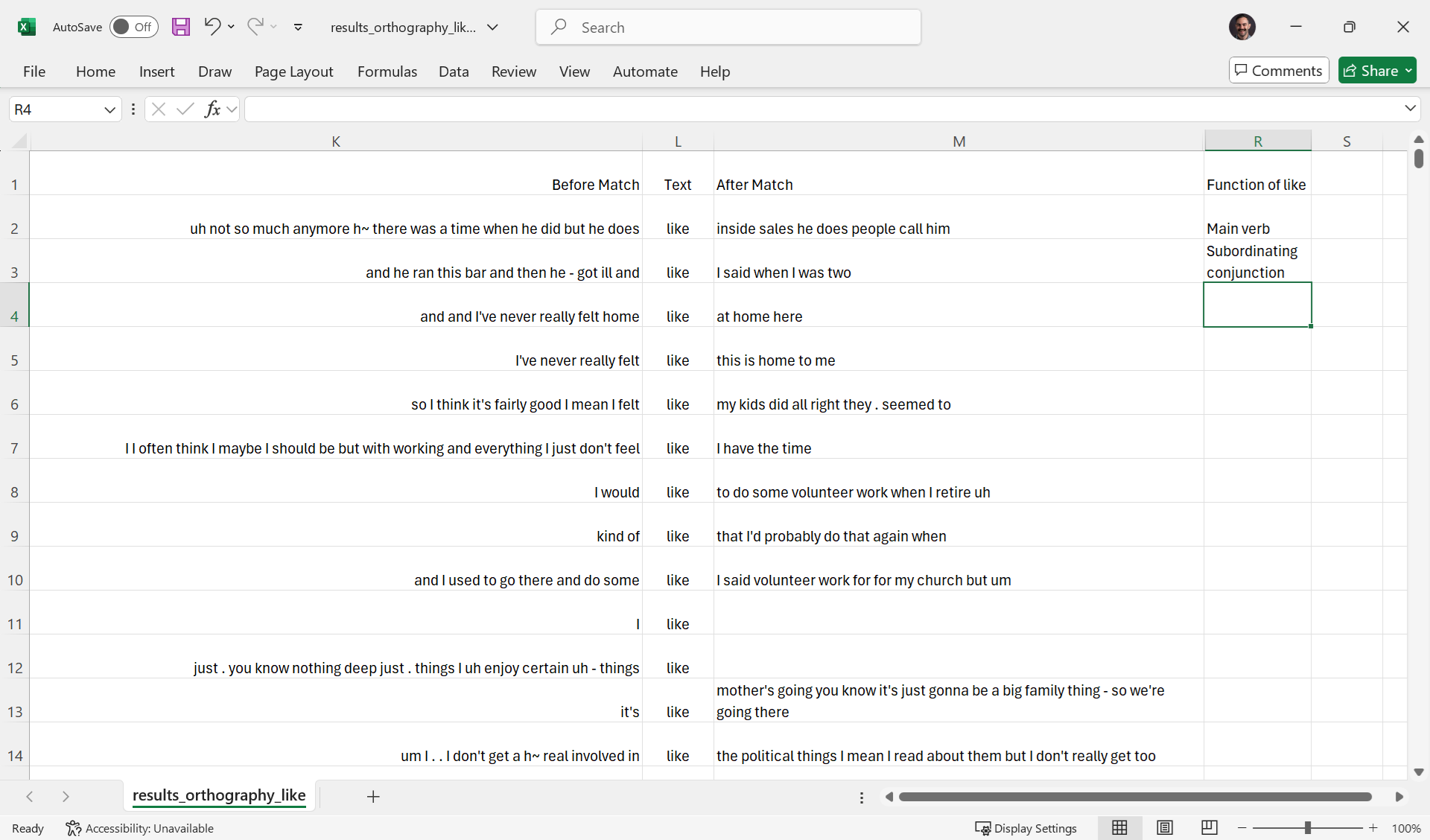
If you want to return to the Search results page interface after you’ve closed APLS, you can reupload your CSV file to the Extract data based on search results page (https://apls.pitt.edu/labbcat/matches/upload).
Viewing tokens on the Transcript page
In some cases, you may need more context than is available on the Search results page or in the Before Match/After Match CSV columns. For example, the third like search result is ambiguous without knowing what comes after “like at home here”. Clicking on a search result on the Search results page will open the Transcript page in a new tab and highlight/scroll to that token. Here’s what it looks like when you click the third like search result:
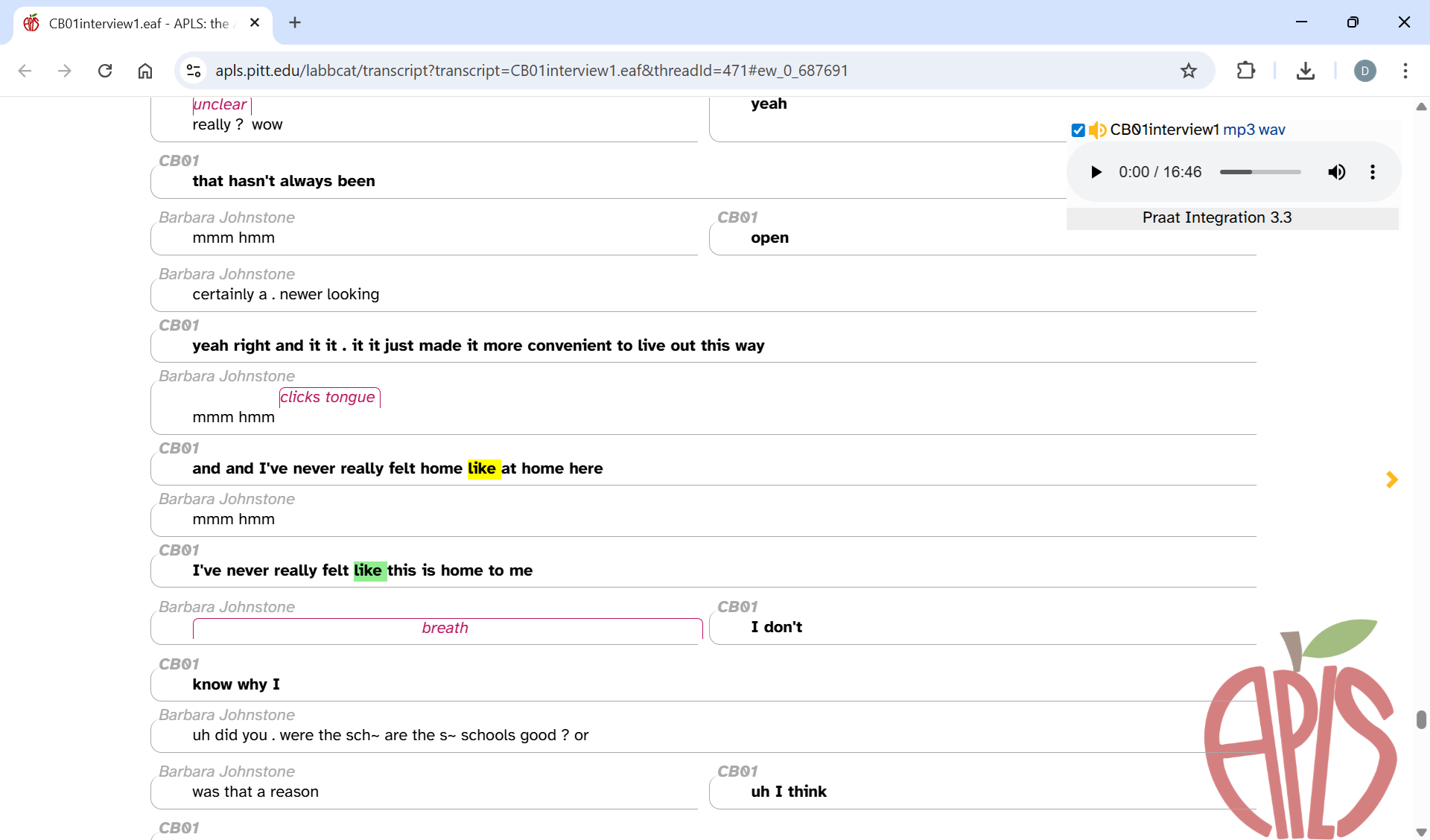
As you can see, the like in “like at home here” has been highlighted in yellow. The next like token (in “like this is home”) has been highlighted in green, and if you scroll elsewhere in the transcript, you’ll see other like tokens highlighted in green too. If you’re working with a CSV, you can access these links in the URL column.
Like on the Search results page, the CSV
URLlinks open the Transcript page, scroll to that token, and highlight it in yellow. However, other tokens aren’t highlighted in green. This is because highlighting other tokens requires APLS to save stored data on search tasks. Once a user closes the Search or Search results page, APLS cleans out the stored search task data to save space.
Coding tokens by listening to audio
In this scenario, coding is done manually by listening to how speakers produce tokens of a variable. This is known as auditory coding. Auditory coding works well for phonological variables (like [ɪŋ] vs. [ɪn] endings in words like working or something) and suprasegmental variables (like creaky voice vs. modal voice). In other words, auditory coding is necessary for coding variables where the different variants don’t correspond to annotations in APLS and can’t be determined from reading the transcript. (See above for why phonological annotations are phonemic, not phonetic.)
One way to do auditory coding in APLS would be to open each search result on the Transcript page and use the word menu to play just the utterance that contains the token. But we’ve created a faster way: CodeTokens.praat. CodeTokens.praat is a program (running within Praat) that makes coding faster and easier by seamlessly integrating with the APLS Search results page, playing tokens one-at-a-time, providing a graphical user interface for selecting variants, and writing your codes to a CSV file:
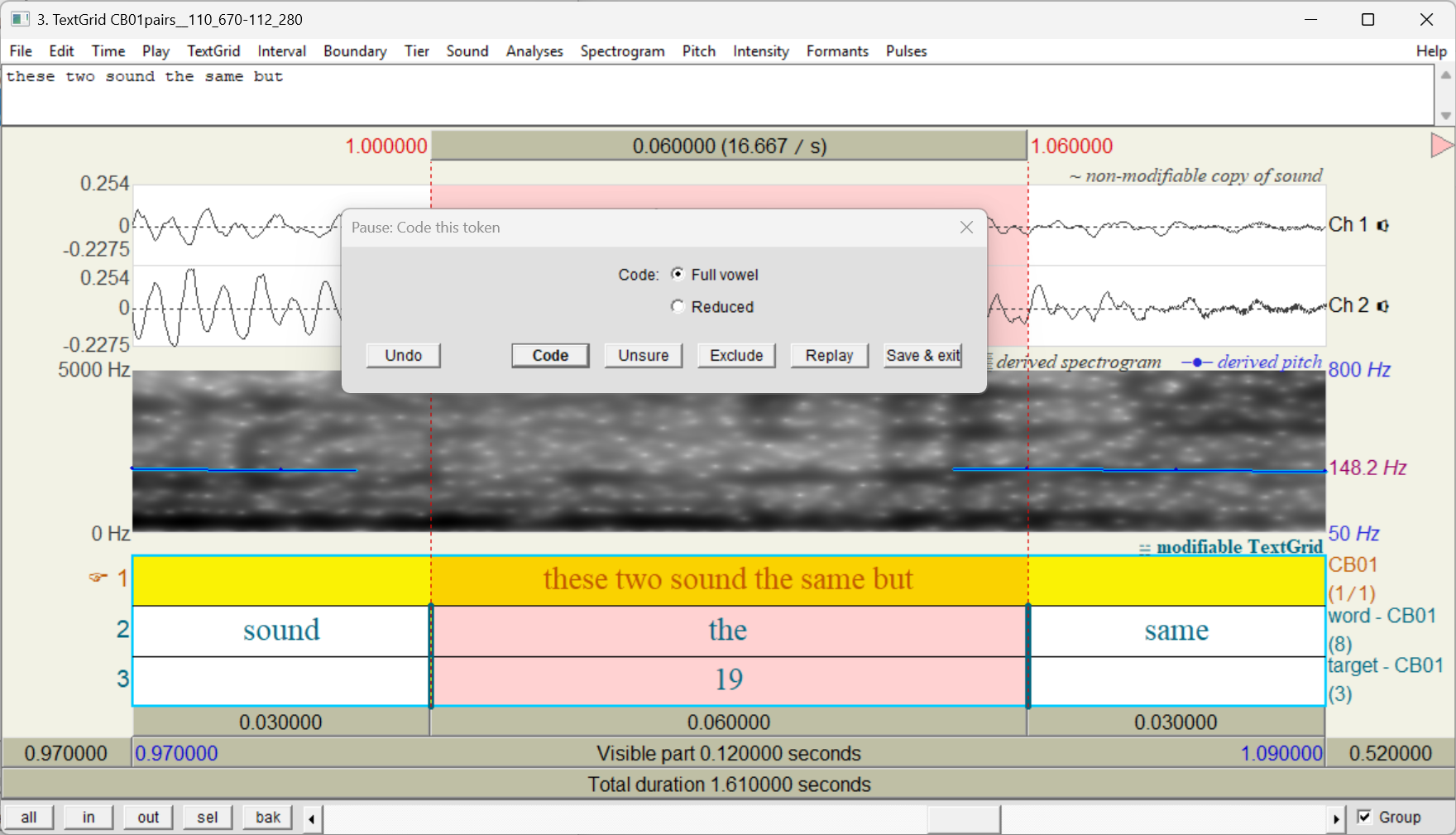
To learn more, visit the CodeTokens.praat documentation page.
Coding predictors
The same token-coding scenarios discussed above apply to coding predictors (aka independent variables or constraints):
- Coding predictors by extracting annotations. Works well when the predictor can come:
- Directly from annotations on an APLS layer (like frequency_in_corpus) or attribute (like gender)
- From relabeled annotations (like providing nicer labels for stress markers or part_of_speech tags)
- From categorized annotations (like categorizing morphemes annotations into
past tensevs.non-past tense)
Unlike coding tokens, this scenario can apply to phonological predictors, as long as the predictor is defined on the level of phonemes rather than surface representations (like the length of an [underlying] consonant cluster).
- Coding predictors by reading context. Works well for predictors that are difficult to extract from APLS annotations, on the level of:
- Discourse (like topic or stance)
- Syntax (like the subject of a verb)
- Coding tokens by listening to context. Works well for predictors that require listening on the level of:
- Segmental phonology (like whether the vowel in the -ing ending is [ɪ] or [i])
- Suprasegmentals (like creaky voice vs. modal voice)
- Discourse (like whether a speaker is being sarcastic)
- Measuring predictors by extracting acoustic properties of each token. Works well for measurable predictors like pitch