
Version history
APLS’s current preview version is 0.5.0 (dated 5 Jun 2026). This version of APLS uses LaBB-CAT version 20251105.1346.
| APLS version | Version date | LaBB-CAT version |
|---|---|---|
| 0.5.0 | 5 Jun 2026 | 20251105.1346 |
| 0.4.4 | 11 May 2026 | 20251105.1346 |
| 0.4.3 | 19 Jan 2026 | 20251105.1346 |
| 0.4.2 | 4 Dec 2025 | 20251105.1346 |
| 0.4.1 | 14 Oct 2025 | 20250819.1454 |
| 0.4.0 | 15 Aug 2025 | 20250430.1502 |
| 0.3.1 | 6 Jun 2025 | 20250430.1502 |
| 0.3.0 | 23 May 2025 | 20250430.1502 |
| 0.2.3 | 6 May 2025 | 20250430.1502 |
| 0.2.2 | 15 Apr 2025 | 20241121.1451 |
| 0.2.1 | 29 Jan 2025 | 20241121.1451 |
| 0.2.0 | 10 Jan 2025 | 20241121.1451 |
| 0.1.4 | 20 Sep 2024 | 20240920.1237 |
| 0.1.3 | 4 Sep 2024 | 20240905.1253 |
| 0.1.2 | 2 Jul 2024 | 20240702.1253 |
| 0.1.1 | 7 Mar 2024 | 20240306.132 |
| 0.1.0 | 2 Oct 2023 | 20231002.152 |
Version 0.5.0
- Date: 5 Jun 2026
- LaBB-CAT version: 20251105.1346
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so existing data is subject to change in minor ways.
New layers/attributes
- Added new prec_pause and prec_segment layers. These are the counterpart to the existing foll_pause and foll_segment layers, and they should make it easier to specify search environments and export data.
- Thanks to Meredith Tamminga for the idea for this layer!
- Added new frequency_from_subtlex layer, which tags words with their word frequency from the SUBTLEX-US corpus of subtitles from 8,388 films. The authors of SUBTLEX-US argue that its frequency measurements represent an improvement over those from Kučera & Francis or CELEX. This layer specifically uses SUBTLEX-US’s
Lg10CDmeasure, the base-10 logarithm of the number of films that the word appears in, on the advice of Meredith Tamminga.- Thanks to Meredith Tamminga for the idea for this layer!
SUBTLEX-US has separate entries for clitics like ‘s, meaning there are no frequency counts for cliticized words like what’s. As a result, words with clitics have no frequency_from_subtlex annotation, including some high-frequency words like it’s (6,920 tokens in APLS). However, CELEX lacks entries for high-frequency fillers like hmm (11,992 tokens in APLS). Here’s how the numbers stack up for the 518,785 word tokens for which hesitation is
False(since hesitations like wh~ wouldn’t be expected to be in either reference corpus):frequency_from_celex annotations 0 1+ frequency_from_subtlex annotations 0 19,836 21,591 1 30,901 446,457 We plan to figure out some way to add frequency_from_subtlex annotations for cliticized words in a future release (perhaps by switching its alignment from “complete interval” to “sub-interval” and tagging base-forms and clitics as horizontal peers).
- Added new word_index layer, which labels each word’s index (e.g., 1st, 5th, 270th) for that participant in that transcript:
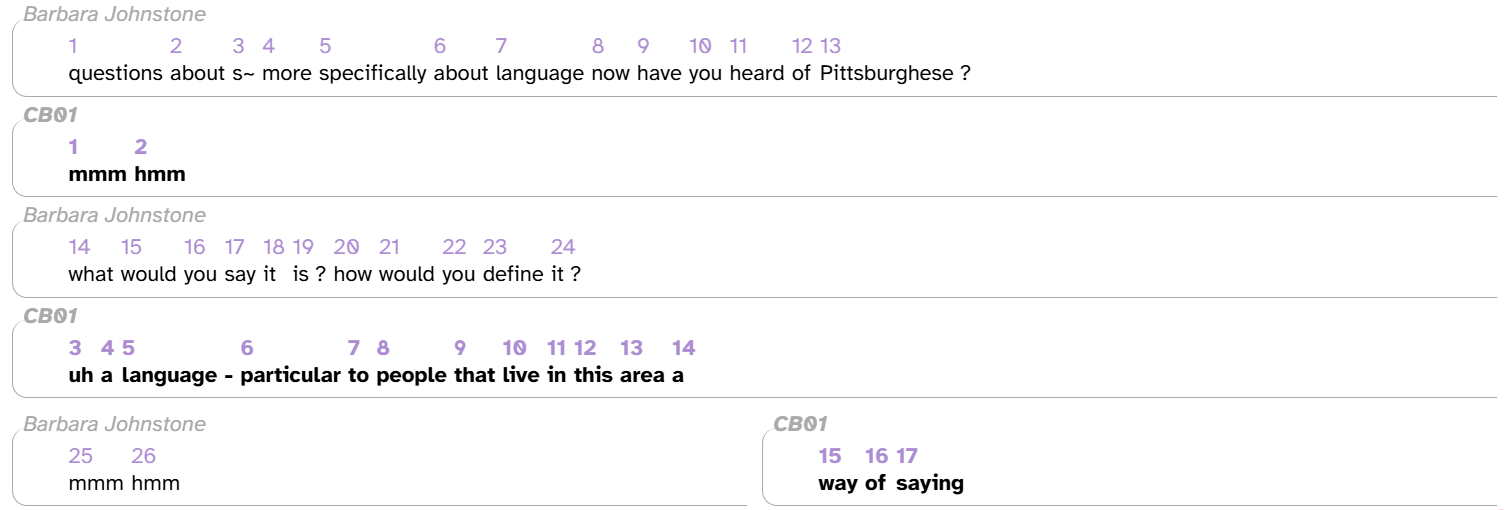 This can be useful for assessing effects of recency (e.g., how many words ago did this speaker use the same word?)
This can be useful for assessing effects of recency (e.g., how many words ago did this speaker use the same word?) - Thanks to James Stratton for the idea for this layer!
- Added new word_count participant attribute. This is useful for things like calculating and comparing speakers’ density of using particular words (e.g., um and uh).
- Thanks to Scott Kiesling for the idea for this attribute!
- Added new tasks participant attribute, which lists the interview task(s) that each main participant has in APLS. This is equivalent to listing the types of all the transcripts in which that participant appears. This attribute is useful for contextualizing why some participants have low word_counts. It’s also useful for filtering participants (if, for example, you want to search only participants who have
interview,reading, andpairstasks).
User interface changes
Below, you can click the GitHub icon  to view code changes on GitHub.
to view code changes on GitHub.
- Pitch measurement on the Process with Praat page
- As of 2023, the Praat authors recommend Praat’s filtered autocorrelation method for pitch analysis instead of raw autocorrelation (which had been the recommended method since 1993). As a result, this is now the default pitch analysis method in APLS. However, users can still use raw autocorrelation (now a drop-down menu option) or specify a custom Praat command if they wish.
Comparison
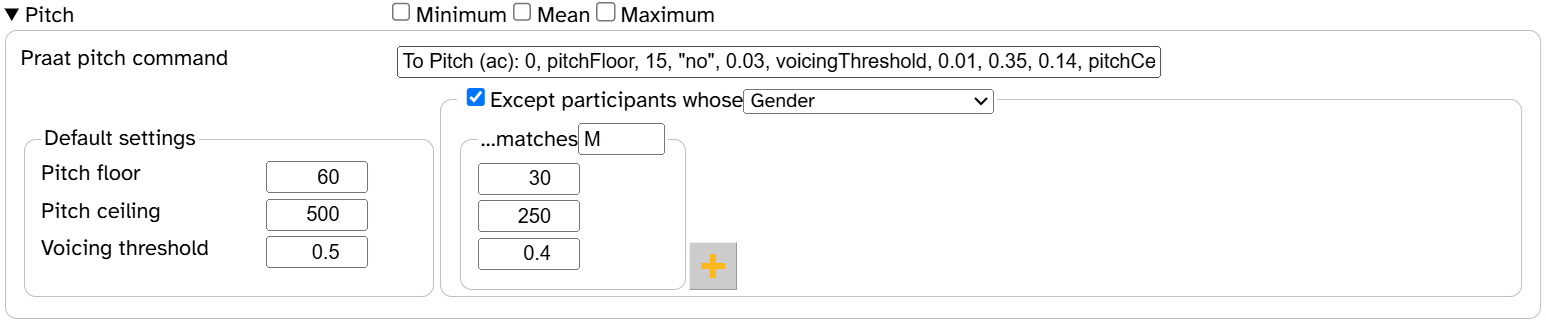
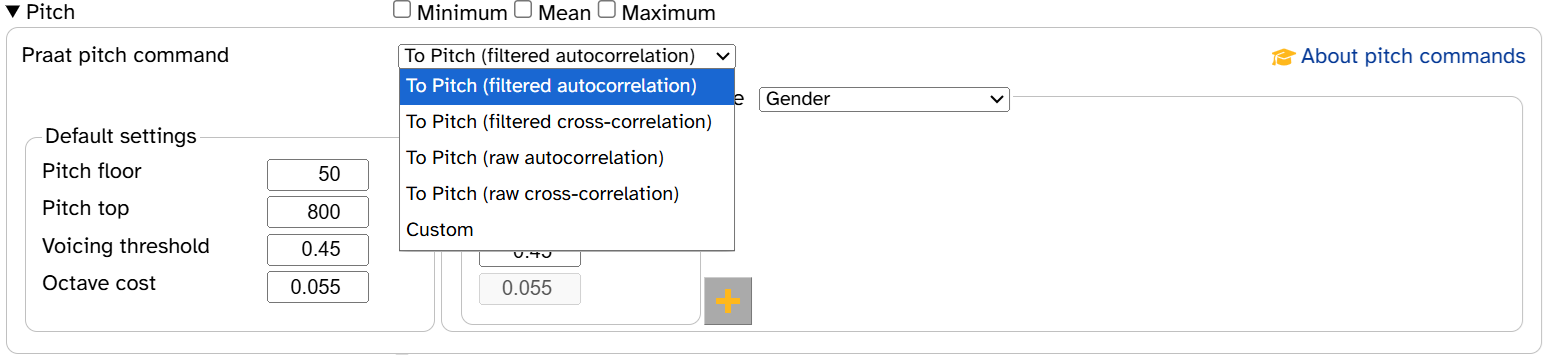
- As of 2023, the Praat authors recommend Praat’s filtered autocorrelation method for pitch analysis instead of raw autocorrelation (which had been the recommended method since 1993). As a result, this is now the default pitch analysis method in APLS. However, users can still use raw autocorrelation (now a drop-down menu option) or specify a custom Praat command if they wish.
-
In the CSV Export panel of the Matches page, the “linked annotations” counter now defaults to returning
alllinked annotations, giving users a fuller picture of linked annotations. - Symbol picker on the Search page
- Previously, syllabic consonants were a subcategory under the CONSONANTS category. This didn’t make sense for layers like foll_segment, since the onset of a syllabic consonant is more vowel-like. Now, syllabic consonants are under VOWELS for foll_segment and CONSONANTS for prec_segment; for all other layers, syllabic consonants are their own category, since we can’t assume a priori whether it makes sense to categorize them as vowels, consonants, or neither.
- To search for a single segment that is either a non-syllabic consonant or a syllabic consonant: type
[, click both CONSONANTS and SYLLABIC CONSONANTS, then type]to close the character class. This will result in the pattern[[pbtdkgfvTDszSZhJ_mnNlrwj][FHP]].
- To search for a single segment that is either a non-syllabic consonant or a syllabic consonant: type
- Previously, for technical reasons, there were no symbols for /ɔ(ɹ)/ and /ɚ/. Now, these are present.
- Previously, syllabic consonants were a subcategory under the CONSONANTS category. This didn’t make sense for layers like foll_segment, since the onset of a syllabic consonant is more vowel-like. Now, syllabic consonants are under VOWELS for foll_segment and CONSONANTS for prec_segment; for all other layers, syllabic consonants are their own category, since we can’t assume a priori whether it makes sense to categorize them as vowels, consonants, or neither.
-
On individual Transcript pages, the word menu has a new Copy transcript text, which copies the word annotations for that utterance to the user’s clipboard.
-
On the Search page, input boxes that accept regular expressions do a better job of checking for errors in regular expressions. In particular, these input boxes now accept regular expressions with nested square brackets (like
[[7][8]]) as valid and reject regular expressions with unmatched[or empty[]. - Other user-experience “quality-of-life” improvements on the Process with Praat page
- For example, previously, if you clicked Pitch or Intensity and configured advanced pitch/intensity settings, you might not have remembered that you also needed to select which measure(s) you wanted to extract. (This generally isn’t an issue for formant measurement since F1 and F2 are selected by default.) Now, if you change any advanced pitch/intensity settings but don’t select a measure, APLS will ask if you’re sure you want to proceed.
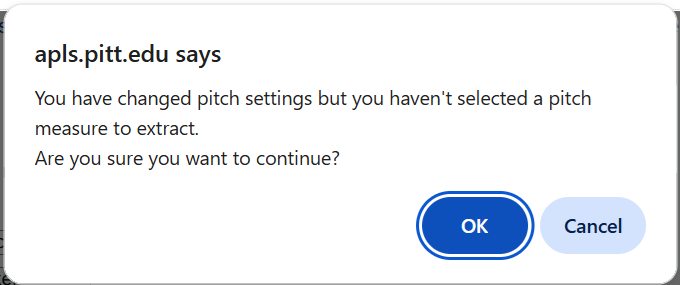
- For example, previously, if you clicked Pitch or Intensity and configured advanced pitch/intensity settings, you might not have remembered that you also needed to select which measure(s) you wanted to extract. (This generally isn’t an issue for formant measurement since F1 and F2 are selected by default.) Now, if you change any advanced pitch/intensity settings but don’t select a measure, APLS will ask if you’re sure you want to proceed.
Updates to existing layers/attributes
- Removed about 6,000 annotations that didn’t belong to any transcript: 5,898 word annotations, 8 orthography annotations, and 10 dictionary_phonemes annotations. These were probably holdovers from earlier versions of the corpus when things were more experimental. This won’t affect any data users might have downloaded; it mostly just affects the “total word count” stats for the corpus.
- Corrected errors in right_channel_participants for 96 transcripts (including all Hill District transcripts).
Corpus status
- Transcript series (40, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH10, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD12, HD16, HD17, HD20, HD23, LV03, LV04, LV06, LV07, LV08, LV09, LV10, LV11, LV16, LV17, LV19, LV20 - Transcripts: 274
- Transcript duration (H:M:S): 45:37:27.63
- Word tokens/types: 530903/11891
- Aligned segments: 1244557
- Annotation layers (26): comment, coronal_stop_deletion, foll_pause, foll_segment, frequency_from_celex, frequency_from_subtlex, frequency_in_corpus, hesitation, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, prec_pause, prec_segment, pronounce, redaction, segment, speech_rate, stress, syllables, word, word_index
Version 0.4.4
- Date: 11 May 2026
- LaBB-CAT version: 20251105.1346
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so the data is subject to change in minor ways.
New layers/attributes
- Added new coronal_stop_deletion layer, the first layer in the
user_contribproject. This layer represents Dan Villarreal’s hand-codes for 14,158 tokens of coronal stop deletion (see ADS 2026 slides for more information). - Added new hesitation layer, which encodes whether or not the word was terminated prematurely. This is the same information that’s represented by the presence/absence of the hesitation marker
~in the word or orthography layers, but putting this information in its own layer is more transparent to users and can make searching easier.
User interface changes
- Some minor tweaks, including:
- Fixing a login bug
- Fixing bugs that only appeared on Firefox
Corpus status
- Transcript series (40, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH10, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD12, HD16, HD17, HD20, HD23, LV03, LV04, LV06, LV07, LV08, LV09, LV10, LV11, LV16, LV17, LV19, LV20 - Transcripts: 274
- Transcript duration (H:M:S): 45:37:27.63
- Word tokens/types: 536801/11891
- Aligned segments: 1244557
- Annotation layers (22): comment, coronal_stop_deletion, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, hesitation, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.4.3
- Date: 19 Jan 2026
- LaBB-CAT version: 20251105.1346
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so the data is subject to change in minor ways.
Updates to existing layers/attributes
Previously, audio files in the LV10 episode had two channels: both participants (interviewer and interviewee) on the left channel and static on the right channel. (This is in contrast to most transcripts, where the interviewer and interviewee are on separate channels.) The segment alignments for the participant LV10 were also rather poor. As a result, we have deleted the right channel (so that LV10 audio files are now in mono) and rerun forced-alignment for LV10. LV10’s segment alignments are much better now, and more of LV10’s utterances have been aligned:
| Layer | Annotations in 0.4.2 | Annotations in 0.4.3 | Change |
|---|---|---|---|
| htk (aligned utterances) | 521 | 546 | +25 |
| segment | 18,533 | 20,219 | +1,686 |
| phonemes | 5,607 | 6,118 | +511 |
| syllables | 7,206 | 7,861 | +655 |
| stress | 7,206 | 7,861 | +655 |
| foll_pause | 5,587 | 6,110 | +523 |
| foll_segment | 18,503 | 20,211 | +1,708 |
| speech_rate | 533 | 556 | +23 |
New layers/attributes
- Added new transcript attributes corresponding to which participant(s) are on which audio channel(s): left_channel_participants, right_channel_participants, single_channel_participants
Corpus status
- Transcript series (40, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH10, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD12, HD16, HD17, HD20, HD23, LV03, LV04, LV06, LV07, LV08, LV09, LV10, LV11, LV16, LV17, LV19, LV20 - Transcripts: 274
- Transcript duration (H:M:S): 45:37:27.63
- Word tokens/types: 536801/11891
- Aligned segments: 1244557
- Annotation layers (20): comment, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.4.2
- Date: 4 Dec 2025
- LaBB-CAT version: 20251105.1346
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so the data is subject to change in minor ways.
New layers/attributes
- Added a new race participant attribute.
- Moved the dictionary_phonemes layer from the ‘phonology’ project to the ‘temp’ project to avoid confusion with phonemes, which is probably what users are more interested in for viewing, searching, and extracting data.
- As a result, version 0.4.2 lists one fewer annotation layer than version 0.4.0, since this count excludes ‘temp’ layers.
User interface changes
- The user interface has been updated in line with the latest version of LaBB-CAT, plus some APLS-specific tweaks.
Third-party software
- Praat has been updated to the latest version (6.4.47 for Windows).
Other
- The server that APLS runs on has received upgrades to memory and computational power.
Corpus status
- Transcript series (40, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH10, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD12, HD16, HD17, HD20, HD23, LV03, LV04, LV06, LV07, LV08, LV09, LV10, LV11, LV16, LV17, LV19, LV20 - Transcripts: 274
- Transcript duration (H:M:S): 45:37:27.63
- Word tokens/types: 536801/11891
- Aligned segments: 1242871
- Annotation layers (20): comment, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.4.1
- Date: 14 Oct 2025
- LaBB-CAT version: 20250819.1454
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so the data is subject to change in minor ways.
User interface changes
The user interface has been updated in line with the latest version of LaBB-CAT, plus some APLS-specific tweaks.
Corpus status
Unchanged from version 0.4.0
Version 0.4.0
- Date: 15 Aug 2025
- LaBB-CAT version: 20250430.1502
This is a “preview” version of APLS. We have uploaded all remaining transcript series; however, we are still tweaking transcript data and refining the UI, so the data is subject to change in minor ways.
New transcripts
- Added transcript series:
- FH10
- HD12
- HD23
- LV10
- LV20
- Added interview files from transcript series CB05and06 (in addition to CB05 and CB06’s individual reading passage and minimal pairs files, which were already in APLS)
Updates to existing layers/attributes
frequency_in_corpus has been regenerated to account for the new transcripts.
Corpus status
- Transcript series (40, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH10, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD12, HD16, HD17, HD20, HD23, LV03, LV04, LV06, LV07, LV08, LV09, LV10, LV11, LV16, LV17, LV19, LV20 - Transcripts: 274
- Transcript duration (H:M:S): 45:37:27.63
- Word tokens/types: 536801/11891
- Aligned segments: 1242871
- Annotation layers (21): comment, dictionary_phonemes, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.3.1
- Date: 6 Jun 2025
- LaBB-CAT version: 20250430.1502
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
User interface changes
- The Search results page now includes information about how long it took APLS to retrieve the matches for that search. This is useful for benchmarking APLS’s performance and determining whether it’s running slower than usual.
Updates to existing layers/attributes
Due to suspected duplicate annotations, all CELEX-based layers were regenerated: frequency_from_celex, lemma, and morphemes. This revealed duplicates in the first two layers, with the vast majority in two interviews (CB10interview2.eaf and CB10interview5.eaf). The changes are summarized below (note that all three layers allow vertical peers, so their annotation counts are greater than orthography).
| Layer | # annotations | |
|---|---|---|
| Previous | Current | |
| word | 435,653 | |
| orthography | 425,769 | |
| frequency_from_celex | 745,211 | 724,032 |
| lemma | 445,332 | 432,601 |
| morphemes | 454,433 | 454,433 |
Corpus status
Unchanged from version 0.2.2
Version 0.3.0
- Date: 23 May 2025
- LaBB-CAT version: 20250430.1502
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
New features
The user interface has been rebuilt on LaBB-CAT version 20250430.1502. For more information, see the User interface page.
Corpus status
Unchanged from version 0.2.2
Version 0.2.3
- Date: 6 May 2025
- LaBB-CAT version: 20250430.1502
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
New features
- Primarily internal-facing changes related to LaBB-CAT updates (see LaBB-CAT changelog)
Corpus status
Unchanged from version 0.2.2
Version 0.2.2
- Date: 15 Apr 2025
- LaBB-CAT version: 20241121.1451
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
New transcripts
- Added transcript series HD16
Corpus status
- Transcript series (35, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD16, HD17, HD20, LV03, LV04, LV06, LV07, LV08, LV09, LV11, LV16, LV17, LV19 - Transcripts: 232
- Transcript duration (H:M:S): 36:56:32.19
- Word tokens/types: 435653/10472
- Aligned segments: 1049168
- Annotation layers (21): comment, dictionary_phonemes, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.2.1
- Date: 29 Jan 2025
- LaBB-CAT version: 20241121.1451
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
New transcripts
- Added transcript series FH19
Corpus status
- Transcript series (34, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH11, FH17, FH18, FH19, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD17, HD20, LV03, LV04, LV06, LV07, LV08, LV09, LV11, LV16, LV17, LV19 - Transcripts: 218
- Transcript duration (H:M:S): 33:53:48.89
- Word tokens/types: 400705/9956
- Aligned segments: 981529
- Annotation layers (21): comment, dictionary_phonemes, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.2.0
- Date: 10 Jan 2025
- LaBB-CAT version: 20241121.1451
This is a “preview” version of APLS. We are still adding new transcripts and refining the UI, so the data is subject to change in minor ways.
New features
- Primarily internal-facing changes related to LaBB-CAT updates (see LaBB-CAT changelog)
Corpus status
- Transcript series (33, all in the
pgh0307collection): CB01, CB05, CB06, CB08, CB10, CB17, FH05, FH07, FH11, FH17, FH18, FH20, FH22, FH23, FH26, FH27, HD01, HD05, HD06, HD07, HD09, HD17, HD20, LV03, LV04, LV06, LV07, LV08, LV09, LV11, LV16, LV17, LV19 - Transcripts: 211
- Transcript duration (H:M:S): 32:47:43.18
- Word tokens/types: 386785/9770
- Aligned segments: 955592
- Annotation layers (21): comment, dictionary_phonemes, foll_pause, foll_segment, frequency_from_celex, frequency_in_corpus, lemma, lexical, morphemes, noise, orthography, overlap, part_of_speech, phonemes, pronounce, redaction, segment, speech_rate, stress, syllables, word
Version 0.1.4
- Date: 20 Sep 2024
- LaBB-CAT version: 20240920.1237
This is a pre-release version of APLS. The version patch number has been incremented to reflect the LaBB-CAT software update. Once APLS and its documentation pages stabilize, versioning will begin in earnest.
New features
- Primarily internal-facing changes related to LaBB-CAT updates
Version 0.1.3
- Date: 4 Sep 2024
- LaBB-CAT version: 20240905.1253
This is a pre-release version of APLS. The version patch number has been incremented to reflect the LaBB-CAT software update. Once APLS and its documentation pages stabilize, versioning will begin in earnest.
New features
- Primarily internal-facing changes related to LaBB-CAT updates
Version 0.1.2
- Date: 2 Jul 2024
- LaBB-CAT version: 20240702.1253
This is a pre-release version of APLS. The version patch number has been incremented to reflect the LaBB-CAT software update. Once APLS and its documentation pages stabilize, versioning will begin in earnest.
New features
- Primarily internal-facing changes related to LaBB-CAT updates (see LaBB-CAT changelog)
Version 0.1.1
- Date: 7 Mar 2024
- LaBB-CAT version: 20240306.132
This is a pre-release version of APLS. The version patch number has been incremented to reflect the LaBB-CAT software update. Once APLS and its documentation pages stabilize, versioning will begin in earnest.
New features
- Primarily internal-facing changes related to LaBB-CAT updates (see LaBB-CAT changelog)
Version 0.1.0
- Date: 2 Oct 2023
- LaBB-CAT version: 20231002.152
This is the first pre-release version of APLS. Once APLS and its documentation pages stabilize, versioning will begin in earnest.