
Getting started
APLS contains sound files with accompanying annotated transcripts that allow the corpus files to be used as structured linguistic data. Once you have an APLS login, you can access APLS through your browser at https://apls.pitt.edu/labbcat.1
On this page
Navigating documentation site
We’ll get into using APLS itself once you have a user account. In the meantime, here are some tips for navigating this documentation site.
Special formatting
This site uses special formatting to denote specific types of information:
- Key terms
- Example: annotation
- Layers and attributes
- Example: orthography
- If you hover over a layer/attribute name, a tooltip will pop up with a short description of the layer/attribute
- Clicking on the name will load its entry in the layer/attribute field guides
- Internal links (i.e., a link to a documentation page or APLS page)
- Example: Special formatting
- External links (i.e., a link that’s not to a documentation page or an APLS page)
- Example: LaBB-CAT
- Input/output text (i.e., something you actually type into APLS or information that APLS displays)
- Example:
CB01
- Example:
- Things you click on in APLS (e.g., a menu option or a link)
- Example: The transcripts page
Navigation across and within pages
You can browse through pages in the left-hand navigation pane. Most pages have a collapsible table of contents toward the top of the page. All headings in the text of a page have a unique permalink; you can copy this permalink by hovering over the heading and clicking the link icon () In the top bar, you can search the documentation (you can type the / key to move your cursor to the search bar without clicking), suggest edits to pages on GitHub, and toggle between light mode and dark mode.
Callout boxes
Throughout these pages are “callout” boxes to help you understand how to use APLS and how it works:
-
Yellow “Note” boxes give important information that might otherwise interrupt the flow of the text.
APLS is powered by the open-source corpus software LaBB-CAT. Throughout this documentation, we’ll use the term LaBB-CAT when we’re talking about the LaBB-CAT software or LaBB-CAT corpora more generally, and APLS for this corpus specifically.
-
Green “Try it!” boxes give you step-by-step instructions on doing some task in APLS. These are especially useful for hands-on learners, but you can skip them if you just need a refresher.
Even if you don’t have an APLS login yet, you can still load the page in your browser.
Go to https://apls.pitt.edu/labbcat. You should see a login box pop up:
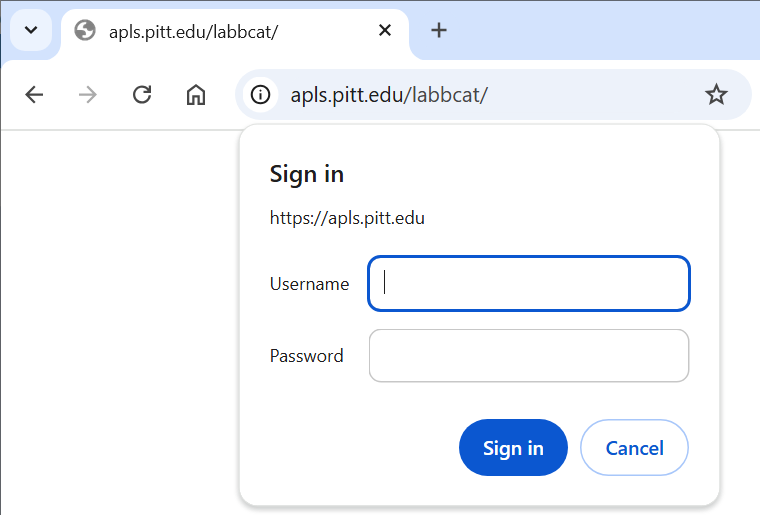
-
Blue “Under the hood” boxes give some details about technical details, design decisions, and/or the history of APLS’s development. They’re meant for especially curious readers, but they’re not crucial to understanding how to use APLS or how it works.
APLS’s original URL was https://labb-cat.linguistics.pitt.edu/labbcat. But the https://apls.pitt.edu/labbcat URL was chosen as an alias because it’s shorter, easier to remember, and less prone to typos.
Sign up
Ready to get started with APLS? Sign up for a user account. We’ll send you a username and temporary password within 1 US business day.
Initial login
Once you have a username and temporary password, you can log in to https://apls.pitt.edu/labbcat:
There are two additional things you’ll only need to do the first time you log in:
-
You’ll see a license (below). Scroll to the bottom and click I Agree.

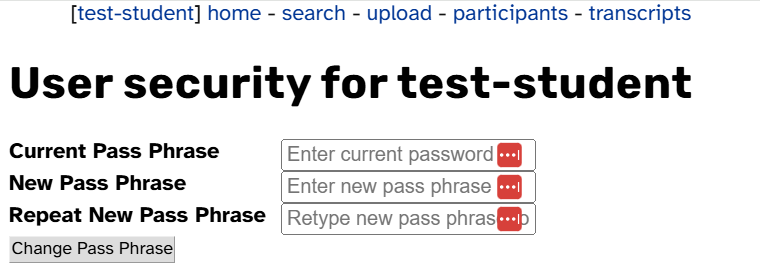
-
Then you’ll see a prompt to reset your temporary password. Enter your new password and click Change Pass Phrase.
Forget your password?
If you forget your password, fill out the password-reset form. We’ll reset your password within 1 US business day.
-
Advanced users can also access APLS via the
nzilbb.labbcatpackage for R, or thenzilbb-labbcatlibrary for Python. These packages have most of the functionality of the browser-based graphical user interface (https://apls.pitt.edu/labbcat), with some added benefits such as reproducibility (e.g., a particular set of search criteria can be encoded in R/Python code rather than described for copy/paste). Even if you plan to mostly use these interfaces, however, it’s a good idea to learn the browser-based GUI first, as it will help you build an intuitive sense for how APLS data is organized. ↩