
Layers: Typology
The layers in APLS can be categorized along some important properties, in terms of how they appear, how they’re generated, how they can be searched, and other properties. This page outlines those categories.
On this page
Scope
Not all annotations in a transcript are equally “wide” (in duration). Some layers contain annotations that pertain to individual words (e.g., part_of_speech), others to individual speech sounds (e.g., segment), and others to multiple words (e.g., redaction). This distinction is captured by layer scope.
Layers can have one of four possible scopes, defined by how long (in time) they can span. From longest to shortest, these are:
| Scope | Meaning | Notes |
|---|---|---|
| Span | Annotations can span beyond an individual turn of talk, up to the length of the entire transcript | |
| Phrase | Annotations can span beyond an individual word, up to the length of an entire turn | |
| Word | Annotations usually span the length of a word | Some word layers (like syllables) have annotations that span just part of a word. These annotations are called horizontal peers, discussed below |
| Segment | Annotations span the length of a speech sound |
What you’ll see in APLS
- Individual transcript pages
- You can usually tell what each layer’s scope is by just glancing at the transcript. For example:
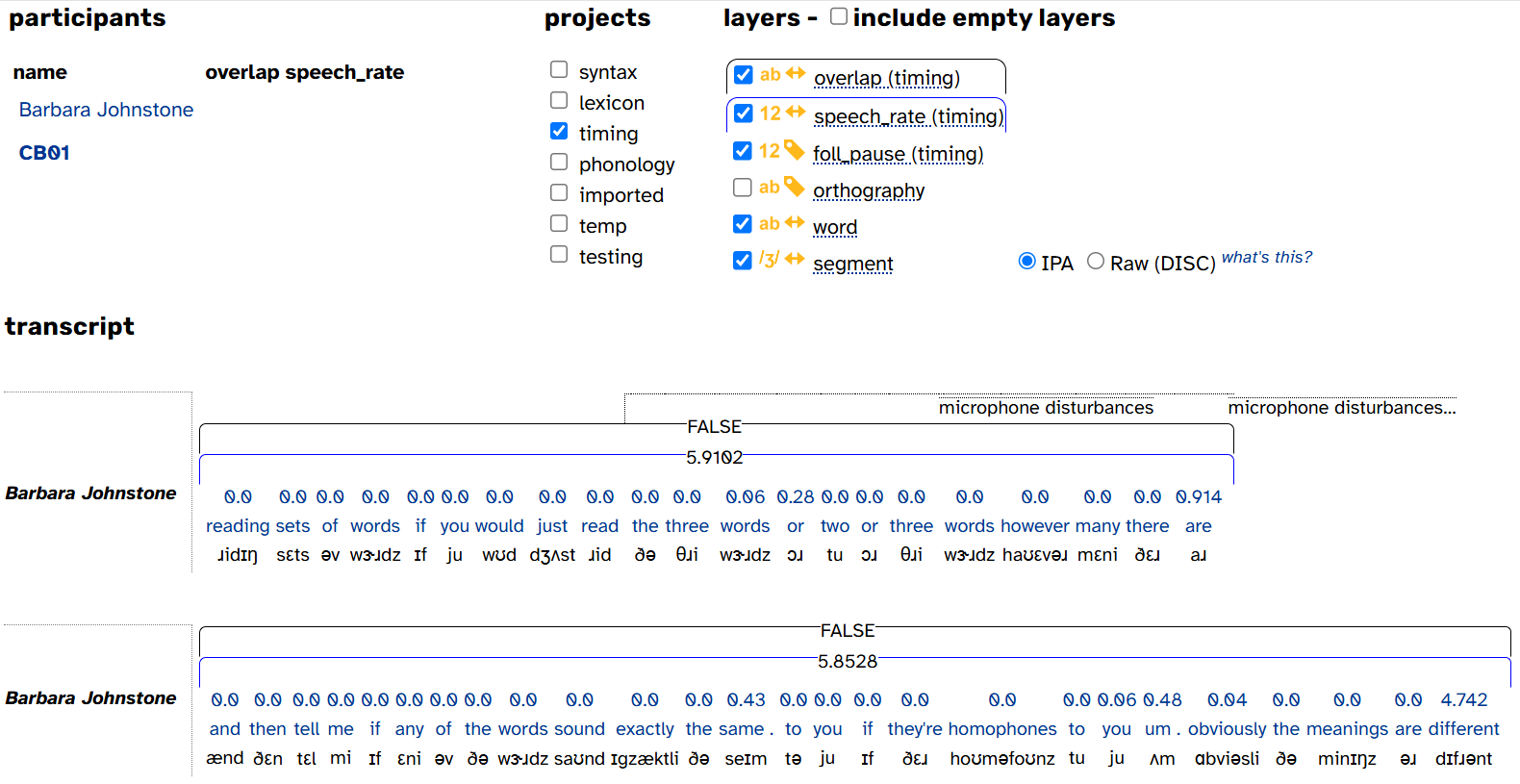
- The noise annotations aren’t bounded by a single line, so noise is clearly a span layer. (Note that transcripts always display the noise and comment layers.)
- Both overlap and speech_rate have annotations that span multiple words, so they are clearly phrase layers. You can tell where these annotations start and end because of the colored arcs above each line.
- Each foll_pause annotation is lined up above each word annotation, so foll_pause is clearly a word layer
- Segment layers like segment aren’t quite as obvious as the other scopes, but you can tell them apart because they’re plain text rather than links, and they’re always underneath word
- Finally, note that layers are always in scope order from longest to shortest
- You can usually tell what each layer’s scope is by just glancing at the transcript. For example:
- Search
- In the layered search matrix, layers are organized into columns by scope:
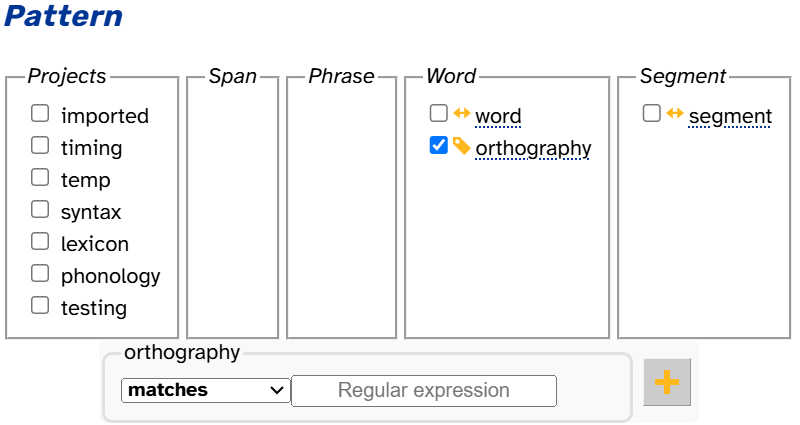 Only a few layers appear when you first load the search page, but you can select projects to show more (see below).
Only a few layers appear when you first load the search page, but you can select projects to show more (see below).
- In the layered search matrix, layers are organized into columns by scope:
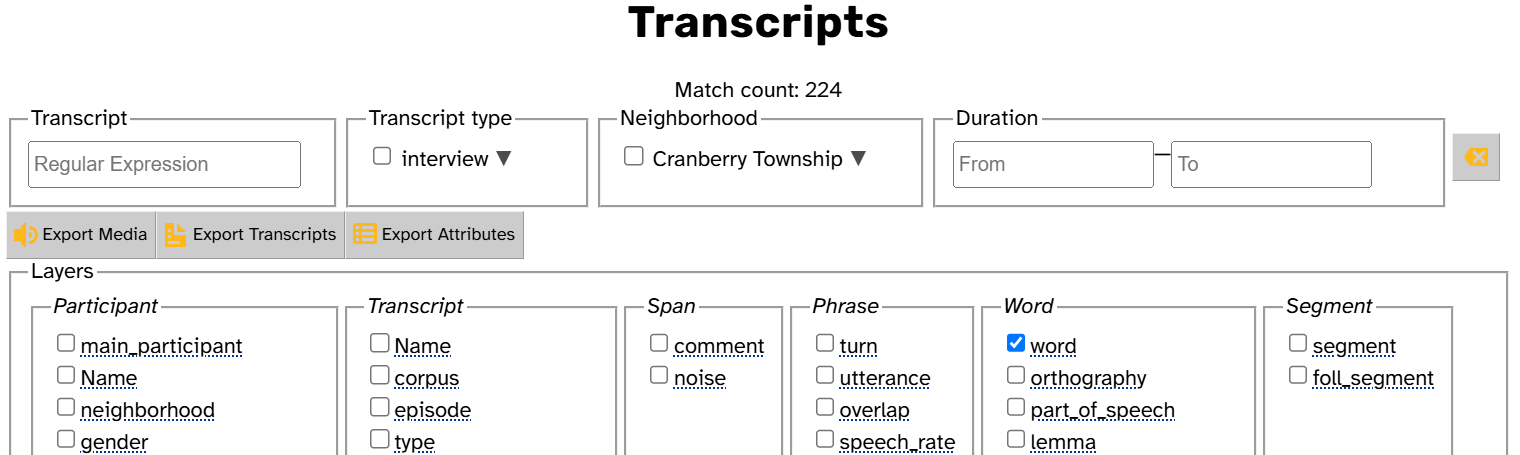
- Exporting data
- Layers are organized into columns by scope
- Depending on how you’re exporting data, there might be additional columns. For example, when exporting a formatted transcript, you can also export participant and transcript attributes:
Layers by scope
| Span | Phrase | Word | Segment |
|---|---|---|---|
|
|
|
|
Alignment and horizontal peers
Some annotations take up just part of their scope, and some annotations take up their entire scope. For example, syllables annotations can take up just part of their corresponding word (if the word is multisyllabic); by contrast, each word has just one frequency_in_corpus annotation. When annotations take up just part of their scope, we say they have horizontal peers: “peers” because they share a scope with other annotations, “horizontal” because we often conceptualize time on an x-axis (i.e., from left to right). This distinction is captured by layer alignment.
Layers can have one of three possible alignments:
| Alignment | Symbol* | Meaning | Notes |
|---|---|---|---|
| Complete interval |  | Annotations always span their entire scope | |
| Sub-interval |  | Annotations can span part of their scope, or their entire scope Annotations that share their scope with other annotations are called horizontal peers | There may or may not be gaps between annotations within a scope. For example, there are usually long gaps between comment annotations within a transcript |
| Timepoint |  | Annotations don’t have a start and end time, just a time | There aren’t currently any timepoint layers in APLS. If we wanted to store vowel measurements in a layer, then we might do so in a timepoint layer (i.e., at the vowel’s midpoint) |
* Used on individual transcript pages and the search page
What you’ll see in APLS
- Individual transcript pages
- In the layer selector, the symbols denote alignments
- When multiple annotations share a word, they crowd into the space above the word (with spaces separating labels). For example:

- Most words in this line have one part_of_speech annotation, but don’t and it’s each have two (n’t is an adverb, and ‘s is a present-tense 3rd-person-singular verb)
- Most words in this line are monosyllabic and just have one syllables annotation, but Family has three syllables annotations and Dollar has two.
- In the layer selector, the symbols
- Search
- In the layer selector, the symbols denote alignments
- [Like with cross-scope search, you can do anchoring] [But you can’t do e.g. multiple syllables within a word]
- In the layer selector, the symbols
- Exporting data
Layers by alignment
Since alignment is relative to the layer’s scope, these are broken down by scope too:
| Scope | Alignment | |
|---|---|---|
| Complete interval | Sub-interval | |
| Span | |
|
| Phrase | |
|
| Word |
|
|
| Segment |
|
|
There aren’t currently any timepoint layers in APLS.
Vertical peers
Some layers allow for vertical peers: 2 or more annotations that occupy an identical timespan. For example, the dictionary_phonemes layer represents all possible phonemic representations of a word, while the phonemes layer represents the speech sounds actually in a word. Since the word the can be pronounced /ði/ or /ðə/, the has two annotations on the dictionary_phonemes layer—but since only one of these is how the word was actually pronounced, the only has one phonemes annotation.
Unlike horizontal peers, which divide the timespan of their scope, we can think of vertical peers as being “stacked” on top of one another within the same timespan.
| Allow for vertical peers? | Symbol* | Meaning |
|---|---|---|
| True |  | A single timespan may contain multiple annotations |
| False | (none) | A single timespan can contain at most one annotation |
* Used on individual transcript pages
What you’ll see in APLS
- Individual transcript pages
- In the layer selector, the symbol denotes layers that allow for vertical peers
- Only one vertical peer is visible on the transcript page
- For example, the dictionary_phonemes layer only shows
ðəfor the word the, even though the has two dictionary_phonemes annotations - To check whether an annotation has vertical peers, view the transcript fragment in Praat instead
- For example, the dictionary_phonemes layer only shows
- In the layer selector, the symbol
- Exporting data
Layers by vertical peers
| True | False |
|---|---|
|
|
Data type
Different layers contain different kinds of annotations. For example, foll_segment annotations are speech sounds, while foll_pause annotations are numbers. This distinction is captured by a layer’s data type:
| Data type | Symbol* | Meaning | Notes |
|---|---|---|---|
| Phonological layers |  | Annotations are labeled with speech sounds | Some phonological layers’ annotations are individual sounds (like segment); others’ are sequences of sounds (like syllables). |
| Numeric layers |  | Annotations are labeled with a measurement | Some numeric layers’ annotations are counts (like frequency_in_corpus); others’ are decimal numbers (like foll_pause). |
| Text layers |  | Annotations are labeled with text | Most text layers’ annotations are normal English spelling (like word) or lowercase English spelling (like orthography) |
| Timing-only layers | (none) | Annotations don’t have a label, only a start/end time | The two timing-only layers represent temporal subdivisions of a transcript: turn and utterance |
* Used on individual transcript pages
What you’ll see in APLS
This distinction is mostly important for search.
- Individual transcript pages
- In the layer selector, alignment is denoted by the symbols in the previous table
- Search
Layers by data type
| Phonological | Numeric | Text | Timing-only |
|---|---|---|---|
|
|
|
|
Notation system
While data type describes the kinds of annotation that different layers contain, notation systems are what those annotations actually look like. In other words, notation systems are the details of how layers represent their data. For example, the phonemes layer represents speech sounds as symbols in the DISC phonemic alphabet, such as fIS for the word fish.
Almost all layers have a primary notation system. (The exceptions are the timing-only layers, turn and utterance, since their annotations don’t have labels—see above.) Some layers have additional notation, depending on what their annotations need to represent. For example, the syllables layer uses the DISC phonemic alphabet for speech sounds plus stress markers for stress, such as 'fIS for the word fish.
Here are brief descriptions of primary notation systems, with links to more details on the notation systems page if applicable:
| Primary notation | Description |
|---|---|
| Boolean | True or False |
| Count | Positive whole numbers |
| DISC | DISC phonemic alphabet |
| Decimal | Decimal numbers |
| English spelling | |
| English spelling (lowercase) | |
| Stress markers | ' (primary stress)" (secondary stress)0 (unstressed) |
| Treebank part-of-speech tags |
Here are additional notations:
| Additional notation | Brief description |
|---|---|
| DISC pause | . |
| Hesitation marker | ~ (at the end of an incomplete word) |
| Morpheme boundary | + |
| Stress markers | ' (primary stress)" (secondary stress)0 (unstressed) |
| Syllable boundary | - |
| Transcription pause/question markers | . (short pause)- (long pause)? (question) |
What you’ll see in APLS
- Search
- [More about how users will interact w/ notation systems than what they’ll see]
Layers by notation system
Primary notation system:
| Boolean | Count | DISC | Decimal | English spelling | English spelling (lowercase) | Stress markers | Treebank part-of-speech tags |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
Additional notation:
| DISC pause | Hesitation marker | Morpheme boundary | Stress markers | Syllable boundary | Transcription pause/question markers |
|---|---|---|---|---|---|
|
|
|
|
|
|
Alignment dependency
Some layers need information about individual speech sounds: which sounds are in a word, and where these sounds begin and end. For example, a word’s phonemes annotation is only possible if the word has segment annotations. Other layers (like part_of_speech) don’t depend on segment annotations. This distinction is captured by alignment dependency:
| Alignment-dependent? | Meaning |
|---|---|
| True | Annotations are only present if the line contains segment annotations—in other words, if the line is aligned |
| False | Annotations can be present even if the line is not aligned |
A layer can be alignment-dependent even if the segment layer isn’t an input to the layer. For example, speech_rate (a phrase layer) takes syllables as input, which takes segment as input; if segment has no annotations in a turn, then syllables won’t have any annotations, which means speech_rate won’t have any annotations.
What you’ll see in APLS
- Individual transcript pages
- [Whole turns w/ big chunks of no annotations]
- Search
- [False negatives in search because turn isn’t aligned]
Layers by alignment dependency
| True | False |
|---|---|
|
|
Project
Different layers pertain to different levels of linguistic representation. For example, morphemes annotations pertain to how words are represented in the lexicon, while speech_rate annotations pertain to the timing of a particular line of speech. As a result, APLS categorizes layers into projects:
| Project | Meaning | Notes |
|---|---|---|
| syntax | Annotations pertain to syntactic structure | |
| lexicon | Annotations pertain to how words are represented in the lexicon | |
| timing | Annotations pertain to timing/rhythm of speech and speaker turns | |
| phonology | Annotations pertain to the speech sounds in a word | All of these layers are phonological layers, see data type above |
| imported | Annotations were imported from the original transcription | |
| temp | Annotations are either metadata on how other layers were generated, or their only job is to provide data for other layers | |
| testing | Test layers that aren’t “ready for prime time” | |
| (none) | Layers whose check-boxes are always shown by default on the search and transcript pages |
What you’ll see in APLS
The main reason projects exist is to reduce visual clutter on the search and transcript pages. When the page loads, only a few layers are selectable (those without a project): [IMAGE] Click a layer’s project to make the layer selectable: [IMAGE]
Unlike other layer properties, projects don’t affect anything about how layers are represented, how you need to search for them, export them, etc.
Layers by project
| (none) | syntax | lexicon | timing | phonology | imported | temp | testing |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
Note: “temp” and “testing” layers aren’t meaningful for end-users, so they’ve been omitted from the other “layers by property” tables on this page.